A bit later than planned here is the fourth instalment on using EPMA interface tables, at the end of the last part the import profile had been created and the tables are ready to be populated so today I will go through the process of using ODI to populate the interfaces tables.
Now you don’t have to use ODI as other methods could be used to populate the tables but I am going to use it as it offers such flexibility around transformations and automation in a controlled environment.
At the start of this mini-series I said I was going to try and approach it from the angle of a classic planning application and convert this into an EPMA world, basically I am going to take the classic planning sample application and transform this to be used in an EPMA model. I think the saying “a picture is worth a thousand words” is going to be very relevant for this part of the series as there are going to be lots of screenshots.
I am using this approach as it is more than likely you will be accustomed to the format required for a classic planning application and it does need transforming before it can loaded into EPMA so this is where ODI comes into its own, it also will provide an insight to the difference in member property naming conventions between classic and EPMA.
First of all I am going to extract the metadata from a classic sample application using the outline loader utility, I have covered using the utility to extract dimensions in a previous blog though it is worth noting this functionality is only available from 11.1.2.1.

Using the utility is very straight forward and only requires one command line per dimension, I extracted all the dimensions for completeness even though I am only interested in Account, Entity, Scenario, Version and Segments.

The files produced are in CSV format and can be opened in a text editor or Excel, if you do open the file in Excel watch out for member formulas as they do cause formatting issues.
The extract using the utility seems to add a leading space to every item after the first column, this will mean that in the ODI integration all the columns will need to be trimmed.
Now that all the source files are place we can look to ODI to transform and load the metadata to the interface tables.
I will go through the step by step process of achieving this in ODI though there is going to be an assumption you are familiar with the core principals of ODI.
I will be using Oracle as the technology for the interface tables but the process will be similar if you are going to use something like SQL server.
A brief description of the process will be define physical/logical information in the topology manager, create the models, design the interfaces to load from the flat files to the EPMA interface tables and then bring it all together with a package.

First the physical information needs to be defined for the flat files and the target EPMA tables.
A Physical Schema was added to the file technology.

The directory where all the source flat files are held is manually entered in the schema boxes.

The physical schema always needs to be mapped to a context and a logical schema, the context I am using is called DEMO and I give the logical schema a name of CLASSIC_FILE_EXTRACTS.



From the dropdowns the schema where the interface tables are held is selected, to make it nice and simple the schema is called INTERFACE.




A Datastore is manually created for each of the flat files as it is not possible to reverse all the files in a Model in one step, the following steps are for the file holding the account metadata.

If the file is accessible by ODI then it is possible to browse to the file, if it is not then the filename would have to be manually entered.


If the file can be accessed by the console then all the columns can be reversed, if the file cannot be accessed by ODI it is easier to temporarily place the file in a location accessible to ODI and the reverse instead of having to manually create all the column information.
I manually updated the lengths to 80 for member/alias columns and increased the Formula column.

The process is repeated for the other flat files that are going to be used to load metadata to the EPMA tables.

A new model is created to hold each the information for each of the EPMA tables.

Oracle technology is selected and assigned to the logical schema that was created earlier in the topology navigator.

In the reverse-engineering section the target EPMA tables that are going to be used in the integrations are selected, these tables were created in part two of this series.


I am just going to cover the Account interface as it is probably the most complex out of all of the dimension builds and gives a good overview.
If the source file did not need any transformation it would be just a case of adding the file to the source mapping area of the interface, adding the target EPMA interface table to the target then applying the one to one mapping and finishing off by setting the Knowledge Modules and options to be used.
This would have been the case if the classic planning member properties matched those of an EPMA enabled planning application, I have no idea why they don’t match as it seems like an obvious decision that would have been made when EPMA was being developed.
It is also worth noting that EPMA is very strict about the naming convention for the member properties and a slight difference such as using lower case instead of upper case for the first character can cause problems.

Above is the completed mappings from source to target and I will now go through each of the columns to explain the mappings.


All of the columns in the mappings use the TRIM function to remove the leading space in the source which is created by default using the outlineloader utility.
In the mapping a CASE statement is used to change the root member from Account to #root, this is required by EPMA and if it is not used then the root member will fail to load and will cause all of its descendants to fail due to missing parent.

CHILD, ALIAS and DESCRIPTION are a simple straight mapping.

The datastorage column of the source file holds the information to whether the member is shared or not with the property value of shared.
The SORTORDER column I have left unmapped for the time being because the rows in the source file are in the correct order.

As the DATASTORAGE property will apply to each of the interfaces I created an ODI function to handle the transformation.

The classic properties for DataStorage are on the left and the EPMA ones are on the right and as you can see there is a slight variation.



I would usually create a function for converting the Data Type as it is used in all dimensions but this time I was just a little bit lazy.
The main differences between classic and EPMA were the initial character needed capitalizing so I used the INITCAP function.
non-currency needed converting to NonCurrency.
The biggest difference between versions is enumeration in classic and SmartList in EPMA, I do agree that SmartList is a much more user friendly naming convention and enumeration stems from the earlier days of planning.


Instead of having to keep repeating mappings for the different columns that require this logic I once again created an ODI function to handle them.







Skip Value is a strange one in classic it is zeros and in EPMA it is Zeroes, both are correct definitions but it is just typical they would differ.


Main difference is non-expense in classic and NonExpense in EPMA but a simple CASE statement takes care of that.


Very similar between classic and EPMA it is mainly just the first character that needs to be a capital in EPMA, once again the CASE statement could have been used instead of DECODE.


Only difference is the first character needs is capitalised in EPMA.


As the number of records to be loaded is small then I find it perfectly fine to use LKM File to SQL instead of the more heavyweight KM’s like “LKM File to Oracle (SQLLDR)”
The KM selected to load from the staging area to the interface table was “IKM SQL Control Append”, no need for flow control and I selected to truncate the table, if there was metadata in the table against a different load id then the truncate wouldn’t have been used and the records matching the current load id would need to be deleted first.
That completes the Account dimension load from a file to the account interface table and the next steps are to be build interfaces for the other dimensions, I am not going to through them as the logic is pretty much the same though I will show screenshots of each of the interfaces for completeness.
Entity

Scenario

Segments

Version

Now to put it all together a package can be used to step through each of the interfaces.

The first step sets the load ID to a value of 1, this could actually be done at run time and instead of setting the variable it could just be declared.

All the interfaces tables have successfully been populated but that is not the end just yet as the metadata has to be imported into EPMA.

For now I am going too manually import the dimensions and this is done from the EPMA dimension library.

From the Type drop down list “Interface Tables” are selected and the profile which created in the last part of this series.
The interface Load ID is also required and set to 1 as that is the number that has been used throughout this series.

So there we go all the dimensions are now populated from the interface tables, if there are any errors these will be logged in the job console.
The application would then need to be deployed to push down the information to planning and essbase.
In reality you wouldn’t want to manually run the import so in the next part of the series I will look at automating this process.
Now you don’t have to use ODI as other methods could be used to populate the tables but I am going to use it as it offers such flexibility around transformations and automation in a controlled environment.
At the start of this mini-series I said I was going to try and approach it from the angle of a classic planning application and convert this into an EPMA world, basically I am going to take the classic planning sample application and transform this to be used in an EPMA model. I think the saying “a picture is worth a thousand words” is going to be very relevant for this part of the series as there are going to be lots of screenshots.
I am using this approach as it is more than likely you will be accustomed to the format required for a classic planning application and it does need transforming before it can loaded into EPMA so this is where ODI comes into its own, it also will provide an insight to the difference in member property naming conventions between classic and EPMA.
First of all I am going to extract the metadata from a classic sample application using the outline loader utility, I have covered using the utility to extract dimensions in a previous blog though it is worth noting this functionality is only available from 11.1.2.1.

Using the utility is very straight forward and only requires one command line per dimension, I extracted all the dimensions for completeness even though I am only interested in Account, Entity, Scenario, Version and Segments.

The files produced are in CSV format and can be opened in a text editor or Excel, if you do open the file in Excel watch out for member formulas as they do cause formatting issues.
The extract using the utility seems to add a leading space to every item after the first column, this will mean that in the ODI integration all the columns will need to be trimmed.
Now that all the source files are place we can look to ODI to transform and load the metadata to the interface tables.
I will go through the step by step process of achieving this in ODI though there is going to be an assumption you are familiar with the core principals of ODI.
I will be using Oracle as the technology for the interface tables but the process will be similar if you are going to use something like SQL server.
A brief description of the process will be define physical/logical information in the topology manager, create the models, design the interfaces to load from the flat files to the EPMA interface tables and then bring it all together with a package.

First the physical information needs to be defined for the flat files and the target EPMA tables.
A Physical Schema was added to the file technology.

The directory where all the source flat files are held is manually entered in the schema boxes.

The physical schema always needs to be mapped to a context and a logical schema, the context I am using is called DEMO and I give the logical schema a name of CLASSIC_FILE_EXTRACTS.

A new Data Server using Oracle technology is created, the username/password to connect to the interface tables are entered

The JDBC connection information to the interface tables is added.

From the dropdowns the schema where the interface tables are held is selected, to make it nice and simple the schema is called INTERFACE.
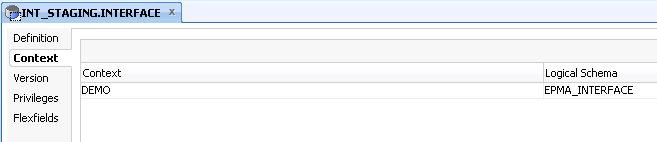
Once again the DEMO context is selected a logical schema name of EPMA_INTERFACE is applied.
This is all that needs to be done in the topology so I can move on to the Designer.
A new model is created for the flat files.

The Model is associated with the file technology and assigned the logical schema that was created in the topology navigator.

A Datastore is manually created for each of the flat files as it is not possible to reverse all the files in a Model in one step, the following steps are for the file holding the account metadata.

If the file is accessible by ODI then it is possible to browse to the file, if it is not then the filename would have to be manually entered.

The format of the file is defined by setting the heading lines to a value of 1, field separator of comma and a single quote text delimiter.

If the file can be accessed by the console then all the columns can be reversed, if the file cannot be accessed by ODI it is easier to temporarily place the file in a location accessible to ODI and the reverse instead of having to manually create all the column information.
I manually updated the lengths to 80 for member/alias columns and increased the Formula column.
The process is repeated for the other flat files that are going to be used to load metadata to the EPMA tables.
A new model is created to hold each the information for each of the EPMA tables.

Oracle technology is selected and assigned to the logical schema that was created earlier in the topology navigator.

In the reverse-engineering section the target EPMA tables that are going to be used in the integrations are selected, these tables were created in part two of this series.

The tables and column definitions are automatically reversed.
Interfaces can now be built as the source and target Datastores have been defined.
Interfaces can now be built as the source and target Datastores have been defined.

I am just going to cover the Account interface as it is probably the most complex out of all of the dimension builds and gives a good overview.
If the source file did not need any transformation it would be just a case of adding the file to the source mapping area of the interface, adding the target EPMA interface table to the target then applying the one to one mapping and finishing off by setting the Knowledge Modules and options to be used.
This would have been the case if the classic planning member properties matched those of an EPMA enabled planning application, I have no idea why they don’t match as it seems like an obvious decision that would have been made when EPMA was being developed.
It is also worth noting that EPMA is very strict about the naming convention for the member properties and a slight difference such as using lower case instead of upper case for the first character can cause problems.

Above is the completed mappings from source to target and I will now go through each of the columns to explain the mappings.

In the second part of this series I went through the LOADID and this numerical value defines what records to load, as this value can change I created an ODI variable which can be applied to all the interfaces and be set at runtime.
All of the columns in the mappings use the TRIM function to remove the leading space in the source which is created by default using the outlineloader utility.
In the mapping a CASE statement is used to change the root member from Account to #root, this is required by EPMA and if it is not used then the root member will fail to load and will cause all of its descendants to fail due to missing parent.
CHILD, ALIAS and DESCRIPTION are a simple straight mapping.
The ISPRIMARY column requires either a value of 1 to define the member as a primary member or 0 to define as a shared member.
The datastorage column of the source file holds the information to whether the member is shared or not with the property value of shared.
The SORTORDER column I have left unmapped for the time being because the rows in the source file are in the correct order.
As the DATASTORAGE property will apply to each of the interfaces I created an ODI function to handle the transformation.

The classic properties for DataStorage are on the left and the EPMA ones are on the right and as you can see there is a slight variation.

The function takes a single input DataStorage value and converts it from classic to EPMA.
This function can simply be applied to the DataStorage target mapping for each of dimension load interfaces.
This function can simply be applied to the DataStorage target mapping for each of dimension load interfaces.
If you are new to ODI functions then it may be worth having a look at the article I wrote in the past about them.

I would usually create a function for converting the Data Type as it is used in all dimensions but this time I was just a little bit lazy.
The main differences between classic and EPMA were the initial character needed capitalizing so I used the INITCAP function.
non-currency needed converting to NonCurrency.
The biggest difference between versions is enumeration in classic and SmartList in EPMA, I do agree that SmartList is a much more user friendly naming convention and enumeration stems from the earlier days of planning.
There
are a number of member properties in classic that are exported as true/false
and in the EPMA interface world the table definition is set up a numerical so
it requires a 1 for true and a 0 for false.

Instead of having to keep repeating mappings for the different columns that require this logic I once again created an ODI function to handle them.
Like most of the mappings there are a number of different
ways to transform the data to get the same result with formula I removed the
quotes from the beginning and end of the syntax and the replaced double quotes
with single quotes.

SMARTLIST,UDA and PLAN1AGGREGATION were straight mappings where the source was trimmed.
MEMBERVALIDAFORPLAN1 was a conversion from true/false to 1/0 so I reused the CONVERT_BOOLEAN function again.
As there is only one plan type in the application the other columns did not require a mapping, it is dependent on how many plan types there are in an application to which target columns would need to be mapped.
MEMBERVALIDAFORPLAN1 was a conversion from true/false to 1/0 so I reused the CONVERT_BOOLEAN function again.
As there is only one plan type in the application the other columns did not require a mapping, it is dependent on how many plan types there are in an application to which target columns would need to be mapped.

The differences between classic and EPMA naming conventions are the weighted averages and capitalisation; the mapping could also have been achieved using a CASE statement instead of the combination of functions I used.

Skip Value is a strange one in classic it is zeros and in EPMA it is Zeroes, both are correct definitions but it is just typical they would differ.

Main difference is non-expense in classic and NonExpense in EPMA but a simple CASE statement takes care of that.

Very similar between classic and EPMA it is mainly just the first character that needs to be a capital in EPMA, once again the CASE statement could have been used instead of DECODE.

Only difference is the first character needs is capitalised in EPMA.
In classic the source plan type is the actual name of the Plan Type but in EPMA it follows the format of Plan1, Plan2, Plan3, PlanCX, PlanWF

As the number of records to be loaded is small then I find it perfectly fine to use LKM File to SQL instead of the more heavyweight KM’s like “LKM File to Oracle (SQLLDR)”
The KM selected to load from the staging area to the interface table was “IKM SQL Control Append”, no need for flow control and I selected to truncate the table, if there was metadata in the table against a different load id then the truncate wouldn’t have been used and the records matching the current load id would need to be deleted first.
That completes the Account dimension load from a file to the account interface table and the next steps are to be build interfaces for the other dimensions, I am not going to through them as the logic is pretty much the same though I will show screenshots of each of the interfaces for completeness.
Entity

Scenario

Segments

Version

Now to put it all together a package can be used to step through each of the interfaces.

The first step sets the load ID to a value of 1, this could actually be done at run time and instead of setting the variable it could just be declared.

All the interfaces tables have successfully been populated but that is not the end just yet as the metadata has to be imported into EPMA.

For now I am going too manually import the dimensions and this is done from the EPMA dimension library.

From the Type drop down list “Interface Tables” are selected and the profile which created in the last part of this series.
The interface Load ID is also required and set to 1 as that is the number that has been used throughout this series.

So there we go all the dimensions are now populated from the interface tables, if there are any errors these will be logged in the job console.
The application would then need to be deployed to push down the information to planning and essbase.
In reality you wouldn’t want to manually run the import so in the next part of the series I will look at automating this process.

Thanks a lot!
ReplyDeleteCan't wait for the next post!
ReplyDeleteGreat Job :)
John,
ReplyDeleteI wonder if you have come across cases where multiple UDAs and Attributes are to be loaded to a single sparse member? How should the interface tables be populated?
Many Thanks!
Derek
John,
ReplyDeleteI find your blogs extremely helpful and I follow them by simple curiosity or by necessity at times.
I do have one question though, could you help me indentify how you got to the part in ODI where the pix shows you are building the LOAD_ACCOUNTS,
where the pic for "interface [Folder: EPMA]" is displayed (right after the statement Interfaces can now be built as the source and target Datastores have been defined.),
in part 4 of Loading to EPMA planning applications using interface tables.
Hi cg,
ReplyDeleteIf you are still having trouble then just drop me an email and explain in a little more detail.
Cheers
John
Are you populating only the "_Hierarchy" table? Or do all four interface tables need to be populated? (_Member, _PropertyArry, _Property)
ReplyDeleteTHanks!
Hi Kris, I am only populating one table in my examples, part 2 goes through the columns in the table
ReplyDelete