I have been meaning to write this blog for a while now though I thought it was probably best until I had covered the main areas for essbase/planning.
You may be in a situation where you have an essbase cube and you want to extract part of a dimension and load this into planning, you could use the same source as the essbase cube does and use ODI to load it straight into planning but there may be occasions when it is best to run the extract from essbase to planning in one go.
In this blog I am going to assume you have read previous blogs and are up to speed with extracting and loading, if you want a recap then you should have a look (
essbase extraction)
and (
sql to planning)
The aim of this exercise to extract part of an account structure in an essbase db and load it into planning.
When you extract metadata from essbase the outputted format is different than what planning uses so you can’t just do a straight extract from essbase and push it into planning, there are a number of ways of achieving the goal and I will try and touch on a couple of them.
I am going to extract all descendants of Profit from the Sample.basic database; I updated some of the properties of the members just for this exercise.

In the planning sample application I added a new member called profit, the members extracted from essbase will be loaded as a child of profit.

Make sure you have a reversed essbase database and planning application, I am going to use the ones I have used in previous blogs.

Now I am going run through the process in stages, the first stage I am going to extract the metadata from essbase and load it into a temporary table, I am going to get ODI to create and manage the temporary table.
First I created the interface

In the diagram I dragged the reversed measures dimension onto the source.
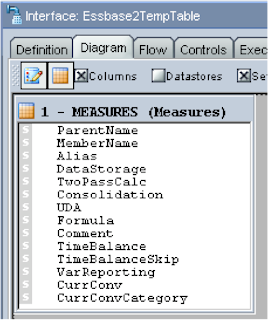
To create a temporary target table, you just have to select the target DataStore and enter a name for it.

Once it has been created to add the columns and mappings to target just right click over a column in the source and select “add to target”.

Once you have gone through all the source columns and added them you should end up with something like.

I made a couple of additions to the target mappings, the first was for TwoPassCalc, when you extract from essbase if the member is set as Two Pass Calc then it will return a ‘T’, planning will be expecting a 1, to get around this I used the replace function to replace anything with T to a 1.

The same sort of situation arises with Variance Reporting, essbase extraction returns ‘E’ if it is set to expense and planning is expecting ‘Expense’, I used the replace function again.

Which ended up with a target DataStore like :-

In the flow diagram the LKM was set as “
LKM Hyperion Essbase METADATA to SQL”
As I am going to extract all the members below profit the options were set to:-
MEMBER_FILTER_CRITERIA = Descendants
MEMBER_FILTER_VALUE = Profit

On the target the IKM used was “
IKM SQL Control Append”
The options that were set were :-
FLOW_CONTROL – the default is yes but for this integration to work it has to be set to No.
DELETE_ALL – set to Yes so each time the interface is run all the records will be deleted.
CREATE_TARG_TABLE – set to Yes, now it will only need to create the temporary target table the first time the interface is run but it doesn’t matter keeping it set to Yes it will just output a warning that the table already exists on future runs of the interface.

When you create an interface that contains a temporary target table the colour of the interface icon will change from blue to yellow.
Executing this interface will extract the metadata from essbase and load it into a virtual temporary table in ODI.
What we need to do next is load the information from the temporary table into planning, now some of the columns of data are still not in the correct format for planning, these are DataStorage, TimeBalance & TimeBalanceSkip, they all extract from essbase one letter and planning needs the full name. I could use a function to change the value into the correct format for example.

This would achieve what I after but it becomes messy and difficult to manage if you want to use it in other interfaces, so what I did was to create mapping database tables to manage this.

One was created for the Data Storage, mapping the essbase extract value to the planning value.

A table was created for Time Balance mappings and one for Time Balance Skip mappings.
I reversed each of these database tables in ODI so they can be used whenever required in interfaces.
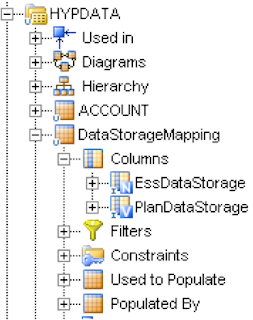
The interface to manage moving the data from the temporary table to planning was created. I dragged the planning accounts DataStore on to the target and the source I dragged the yellow temporary table interface on to the source, any columns that could be were auto-mapped.
Next I mapped all the other columns that have a straight 1:1 mapping like ParentName, MemberName etc.

Ok, I have to use the mapping tables previous created to return the correct value for planning, first I dragged the Data Storage mapping table onto the source and from the temporary table I highlighted DataStorage and dragged it on to the EssDataStorage column of the mapping table, this creates a join between the two tables on them columns.

Now that the join has been created in the target I can use the mapped planning column “PlanDataStorage”

So basically if say the essbase temporary extract table contains ‘N’ for a data storage record, it will map the ‘N’ to the data storage mapping table and return the value in the planning mapping column which would be ‘Never Share’
Next I dragged the Time Balance mapping table onto the source and created a join between the two tables and used the planning column for the target mapping.

As Time Balance doesn’t always have a value set, the temporary table can contain blanks, this will cause the mapping to ignore blank values and not return the records, to get around this in the mapping you set to bring back all the values even if there is no join.

This will mean if the temporary table does contain blank values it will still return the value.
I repeated the same process for the final table “Time Balance Skip”

One final mapping I had to do was for the planning “Account Type”, this is because if “Variance Reporting” is set to “Expense” then the account type will need to be “Expense” otherwise planning will reject the record as it won’t validate, so I set the mapping to be the same value of “VarReporting” as it will only be “Expense” or blank.

In the flow section most of the settings will be standard, all LKMs will be “
LKM SQL to SQL” and the IKM will be “
IKM SQL to Hyperion Planning”
The only option I had to change was
SORT_PARENT_CHILD to Yes this is because the extract from essbase is not going to be exactly the correct order for planning, so setting this option will make sure that everything is in the correct parent/child order, please be aware though if you are updating a lot of members this will slow down the process and may have to look at alternatives.

To run through the process you need to execute the first interface that creates and populate the temporary table and then execute the interface to load and map the values in the temporary table into the planning dimension

The members from essbase and their properties should end up beginning loaded into planning.
You can automate this process by using a package but I am going to leave that until the next time when I will go into more detail.


















































