In part 1 I went through simple journalizing, today I am going to look at using consistent set journalizing. Consistent set journalizing tracks changes to a group of the model’s datastores, taking into account the referential integrity between the datastores.
I am going to use the CDC on two tables that hold planning dimension information; one table has the parent/child/alias details and a primary key of ID.
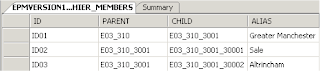
The second table holds the member properties.
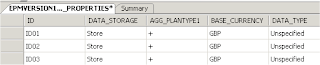
The referential integrity is set on the ID column meaning a record cannot be inserted into the table unless the ID exists in the member’s table.
The idea of today’s example is that I am going to capture updates to these tables and then update planning with the changes, the principle of using consistent journalizing is pretty much the same as using simple so I will assume that you have read part 1 so I don’t have to repeat too much.
A new model was created and the above two tables reversed.
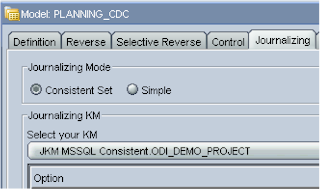
This time the consistent set option was chosen under the Journalizing tab
Next step was to add both the tables to use CDC, right click over the datastore and select.
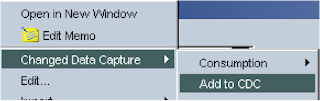
Now when using a group of datastores you have to make sure that the order of the tables is set up correctly, for instance in my example the members table must be before the properties table to preserve the referential integrity.
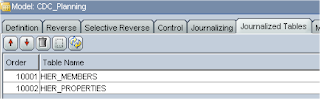
If you click on the organize tables icon in the journalized tables tab it will set up the order by basing it on the tables foreign keys.
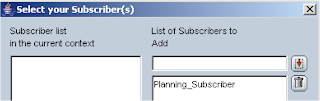
The subscriber can now be created just like when working with simple journalizing.
Once this is applied a session runs to create the subscriber database table, also four extra tables are created these tables are not created when using simple journalizing.
SNP_CDC_SUBS SNP_CDC_SET
SNP_CDC_SET
The other two tables created are
SNP_CDC_SET_NAME &
SNP_CDC_OBJECT, these tables are not populated until the journal is started.
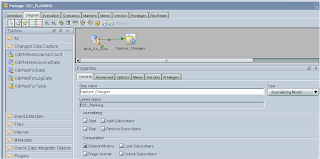
Now the journal can be started by right clicking the model > Changed Data Capture > Start Journal
The session creates the tables, views and triggers required for journalizing.
The table
SNP_CDC_OBJECT holds the information about what has been created.
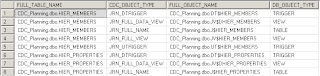
As you can see triggers are created on the two tables that are going to be monitored for changes (
HIER_MEMBERS and
HIER_PROPERTIES)
Tables are created which will hold the information about the changes (
J$HIER_MEMBERS &
J$HIERPROPERTIES)
The window_id field relates to the information stored in the
SNP_CDC_SET table, the ID field relates to the ID in the monitored table.
When a change happens to the monitored tables, the trigger is fired and this table will be populated with the ID of the record.
Views are also created which will display any changes that have occurred.
The process of how the changes are tracked in the database tables is a lot more complicated and involved than when using simple journalizing, I am not going to go into the depths of that detail and concentrate more on how to set the process in ODI.
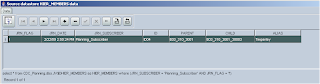
The next stage is to set up the interface that will load the changes into planning, the two datastores are dragged onto the source, and the join between the two tables is automatically created. Just like with simple journalizing you need to tick the “Journalized data only box” which creates three extra journal fields to the datastore (
JRN_SUBSCRIBER,
JRN_FLAG,
JRN_DATE)
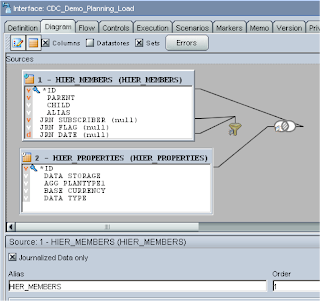
The automatically generated filter needs updating to change the name of the subscriber to the one you are using.
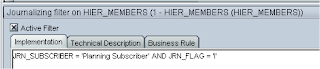
I also added to the filter so only inserts/updates to the table are retrieved; the rest of the interface is set up just like you would for any of loading metadata to planning.
After inserting a record into the monitored datastores you can view the changes from ODI using “Changed Data Capture” > Consumption > “Extend Window”
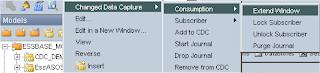
This will execute a session that computes all the changes to the datastores.
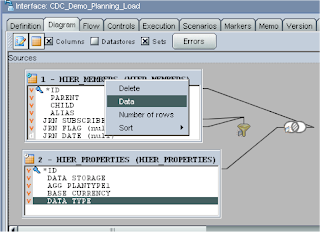
Selecting to display the data uses the SQL view to retrieve any records where updates have occurred.
Executing the interface will load any updates straight to planning, to reset the journal capturing after you have run the interface can be achieved by using “Changed Data Capture” > Consumption > “Purge Journal”
This is fine but you need to be able automate using the “Extend Window” and Purge functionality; this can be performed in a package.
Before I move on to the package I duplicated the interface and removed the properties table, updated the filter to retrieve records where the flag = ‘D’ which means it would retrieve journalized records that have been deleted, on the target I added ‘Delete Level 0’ to the operation column. This interface will now remove any members from planning where they have been removed from the journalized datastore.
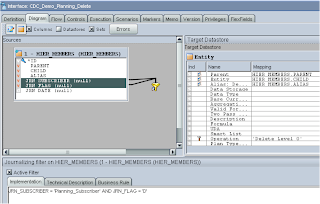
Right, on to the package, the first step is just like I showed in Part 1 by using the ODI tool “
OdiWaitForLogData”
The only difference being that with consistent set journalizing you can’t use the “Table Name” parameter and have to use the CDC Set parameter.
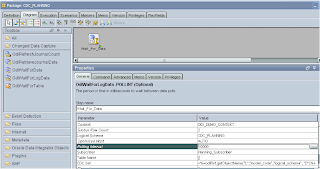
In the CDC Set parameter it needs to be the name of your logical schema and model name, this can be retrieved by using an ODI API function, the code needs to be set as :-
<%=odiRef.getObjectName("L","model_code","logical_schema", "D")%>In my example the logical schema is called CDC_PLANNING and the model CDC_Planning so the API function required to be updated to :-

Now to perform the equivalent function of “Extend Window”, drag the model onto the diagram and set the type to “Journalizing Model” and check the “Extend Window” box.
The two interfaces that load any updates and remove members are dragged onto the diagram.
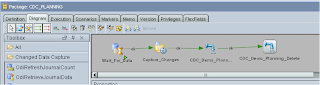
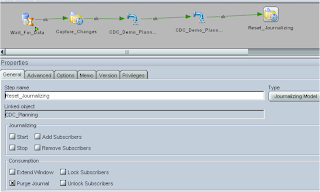
Now that the planning loads have been run we need to reset the journalizing by using the purge command, this can be done like before by dragging the model on to the diagram but this time making sure the “Purge Window” box is checked.
I thought this would be the end of the story but when the purge was run it didn’t reset the journal so the details were still held in the journal tables (
J$HIER_MEMBERS &
J$HIER_PROPERTIES) which meant if I ran the process again it would load the same records again.
I will try and explain why this is happening and how to overcome it, if you are not interested in the techie bits then I would skip this section in case you fall asleep.
When you run the command “Purge Journal” it carries out the following steps.

So say in my example I had the values
CUR_WINDOW_ID = -1,
CUR_WINDOW_ID_DEL= -1,
CUR_WINDOW_ID_INS = -1The table would now hold

The next stage is that it updates the journal tables with the value from
CUR_WINDOW_ID_INS
So if you have updated any records then they will exist in the journal table and will be tagged with the value in
CUR_WINDOW_ID_INS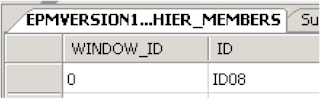
I had already inserted a record into the table I was monitoring so the window_id column was updated.
It repeats this process for each journal table and follows a similar process for any deletions but uses the value from
CUR_WINDOW_DELOk, so what happens when a purge is run; well the following SQL is run for each journal table.
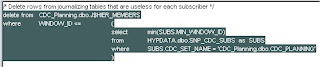
This time it is deleting any values in the journal table where the window_id value is less than or equal to minimum value in the min_window_id column of the
SNP_CDC_SUBS table.

So the logic is delete anything in the journal table where the window_id is less than or equal to -1, this means nothing will be deleted so the purge in this circumstance is doing nothing.
This is where the CDC functions Lock Subscriber and Unlock Subscriber come into play.
If you run the Lock Subscriber function and select the subscriber it carries out the following.

The question mark relates to the subscriber that was chosen, it runs some jython code that populates the question mark with subscriber info.
It is updating the
SNP_CDC_SUBS table with values from the
SNP_CDC_SET table, so after it has completed the
SNP_CDC_SUBS table in my example looks like :-

Running the purge now would still not result in any records being deleted because the
MIN_WINDOW_ID value has not changed.
So finally lets see what happens when the Unlock Subscriber function is run.

This updates the
SNP_CDC_SUBS table and sets the
MIN_WINDOW_ID value to the value of
MAX_WINDOW_ID_INS which results in

So now there is a value of 0 in the
MIN_WINDOW_ID column and running the purge will this time delete records from the journal table
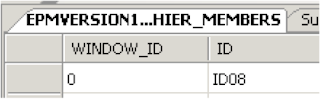
In the journal table the
WINDOW_ID column is 0 and the purge command logic will delete anything which is less than or equal to the
MIN_WINDOW_ID value (0)
This is what the documentation has to say about “Lock Subscribers”
Although the extend window is applied to the entire consistency set,subscribers consume the changes separately. This operation performs a subscriber(s) specific"snapshot" of the changes in the consistency window. This snapshot includes all the changeswithin the consistency window that have not been consumed yet by the subscriber(s). Thisoperation is implemented using a package step with the Journalizing Model Type. It shouldbe always performed before the first interface using changes captured for the subscriber(s).Basically if you want to capture changes to the subscriber you must use this function to be able to capture correctly or you will end up like I did the first time I tried to purge the journal.
I thought I would cover what happens in case the same thing happens to you.
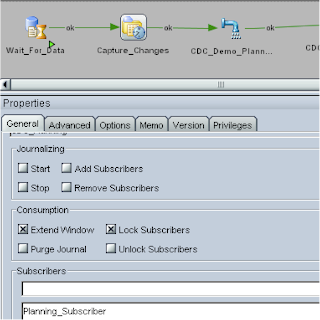
Back to the package, I updated “Capture_Changes” to include “Lock Subscribers” for the subscriber I was using
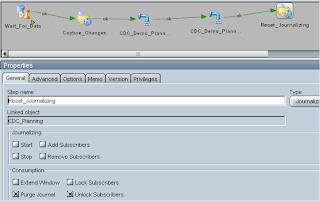
I updated “Reset_Journalizing” to include the “Unlock Subscribers” function and added the subscriber.
Finally I generated a scenario and added the OdiStartScen utility to the diagram, this executes the scenario again which is a much more cleaner and sensible way than just looping back to the first step, if you loop straight back it can cause problems such as the logs growing out of control. I regenerated the scenario so it took into account the last step.
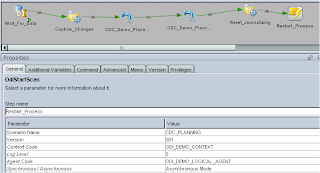
Once the scenario is executed it will wait until 2 records have been updated and then run the journalizing process that captures the records, then the interfaces are run to load metadata into planning, finally the journals are purged and the process will be started again.
I know that I could of created just once interface to handle both the updates and deletes to planning by using the inbuilt functions to change the operation parameter but I just wanted to highlight what could be achieved if you wanted to split loads out.
Well that’s me done for today, time for a bit of a break I think.








































































